Lev Goncharov
Infrastructure simplifying engineer
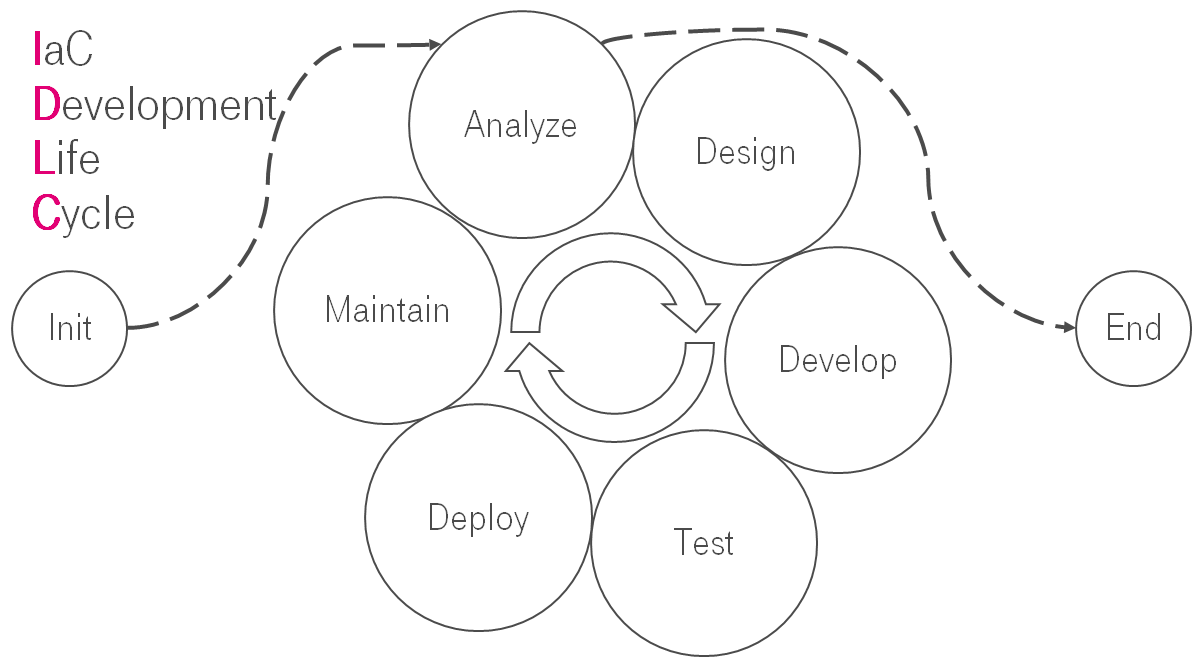
IaC Development Life Cycle
Date: 2021-08-27
Осмелюсь предположить, что многие слышали про SDLC (Systems development life cycle). Но что, если все то же самое происходит с IaC?
Configuration Management
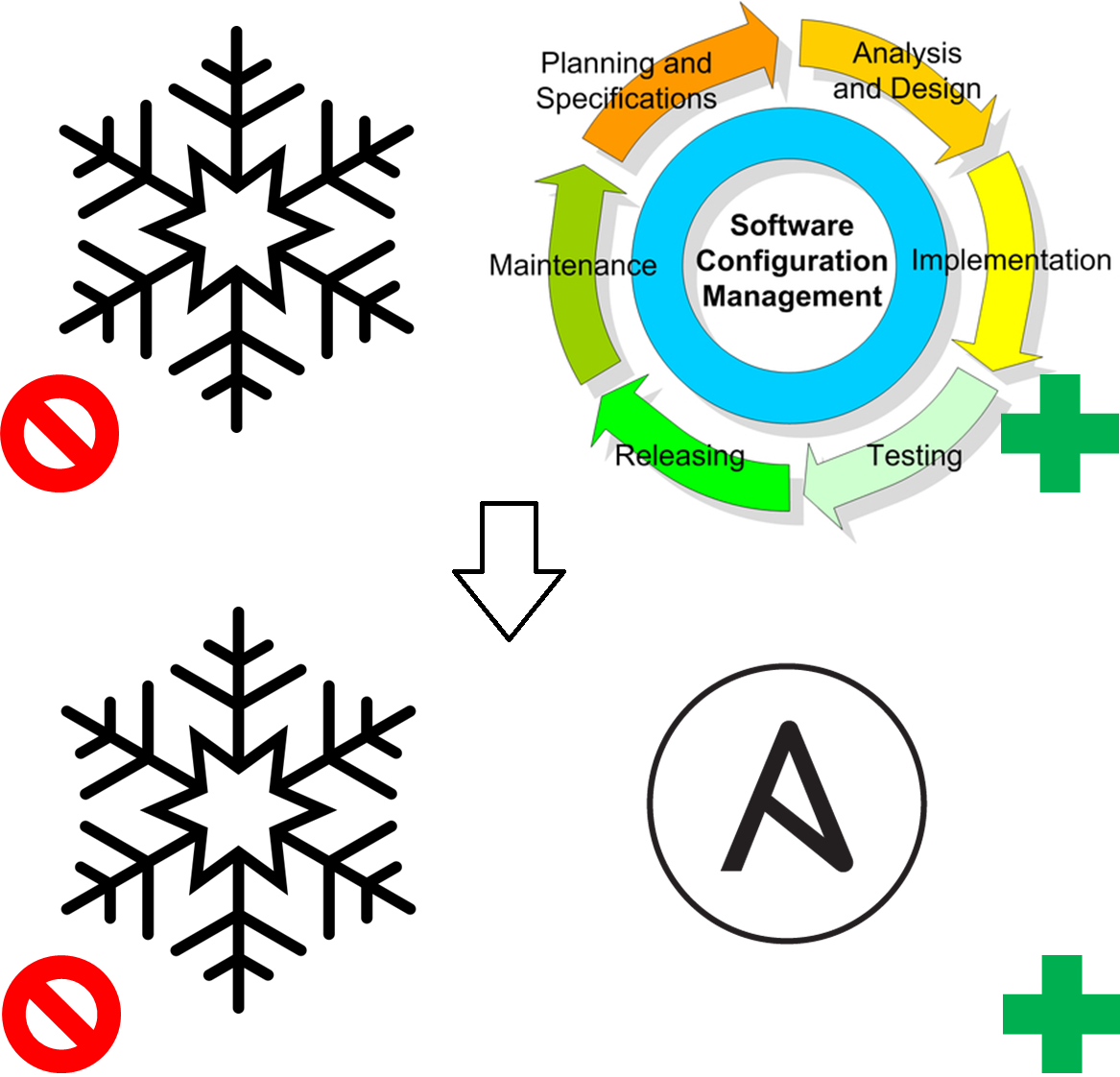
Еще лет 10-20 назад было популярно использовать Configuration Management (тут можно вспомнить ITIL/ITSM). Этот подход позволял вместо уникальных, как снежинки, серверов получать воспроизводимые, надежные системы и структурировать хаос, упорядочить процессы. В подноготной это сводилось к раскладыванию файлов с правильным содержимым по серверам и запуску определённых сервисов с нужными правами. Со временем появились CM решения, такие как CFEngine / Chef / Puppet / Ansible, которые позволяли представить целевую конфигурацию сервера в виде кода и “снять головную боль”.

Ок. Используем CFEngine / Chef / Puppet / Ansible, т.к. ITSM/ITIL отжили своё. Звучит, конечно, хорошо, но как-то пришлось мигрировать с самописного configuration management решения на Ansible, и это заняло 18 месяцев. Порядка 80% времени из этой миграции заняло создание процессов вокруг IaC. Недостаточно просто положить вашу инфраструктуру в git, чтобы появился IaC / gitops, должны существовать процессы вокруг.
IaC Development Life Cycle
В моей голове выстроилась картинка, аналогичная SDLC. Что изменения в IaC цикличны и, как правило, идут по одному пути. Давайте разбираться.
Preliminary analysis
Прежде чем вносить какие-либо изменения, начинать делать что-то новое, необходимо “на лаптях”, оценить предстоящие работы и ответить на 3 простых вопроса:
- Зачем всё это? Пример: хочу добавить k8s на проекте. Зачем? Чтобы была строчка в резюме? Чтобы решить проблему распределения ресурсов? А это не переусложнит инфраструктуру?
- Есть ли время? Пример: хочу k8s, но готов потратить 4 часа. на все. А этого точно хватит?
- Достаточно ли знаний? А точно осилю предметную область? А сложно потом найти будет коллег, знающих эту технологию?
Если на все вопросы есть ответы, то супер - делаем. Если хотя бы один ответ “нет”, то необходимо крепко подумать, а не закончится ли фэйлом все?
Analyze

Если решились на внесение изменений, то все начинается с анализа. Вот что вы видите на картинке? Набережная возле офиса Deutsche Telekom IT Solutions, 3 человека на прогулке. Случайность? Нет! Это идет анализ предстоящих изменений. Да-да, раньше, когда быть в офисе было обыденностью, мы с коллегами каждый обед гуляли по набережной и обсуждали всякие рабочие вопросы, проблемы, придумывали решения. Более того, по личным ощущениям есть коррелляция между небольшой, монотонной физической нагрузкой и мозговой активностью.

Безусловно, существуют и более формальные механизмы анализа, чтобы понять, куда развиваться, какие изменения вносить. Классическая ретроспектива - один из таких механизмов:
- Наклеили стикеры на доску
- Обсудили, что хорошо, что плохо, что улучшить.
- Сделали выводы, наметили план работы
На каждый чих ретроспективу проводить не будешь, да и современные реалии накладывают ряд ограничений. Но существует множество online-инструментов для проведения ретро. Но техники все те же самые.
Design

Родилась идея, мы ее проанализировали, и теперь начинаем продумывать, как и что делать, спускаться в детали:
- Собирается инфраструктурная команда
- Берет маркеры
- Начинает рисовать что-то на доске

Или если погода хорошая, выходили во внутренний дворик офиса и рисовали там за столами. Но как это сейчас делать, когда команды распределенные?
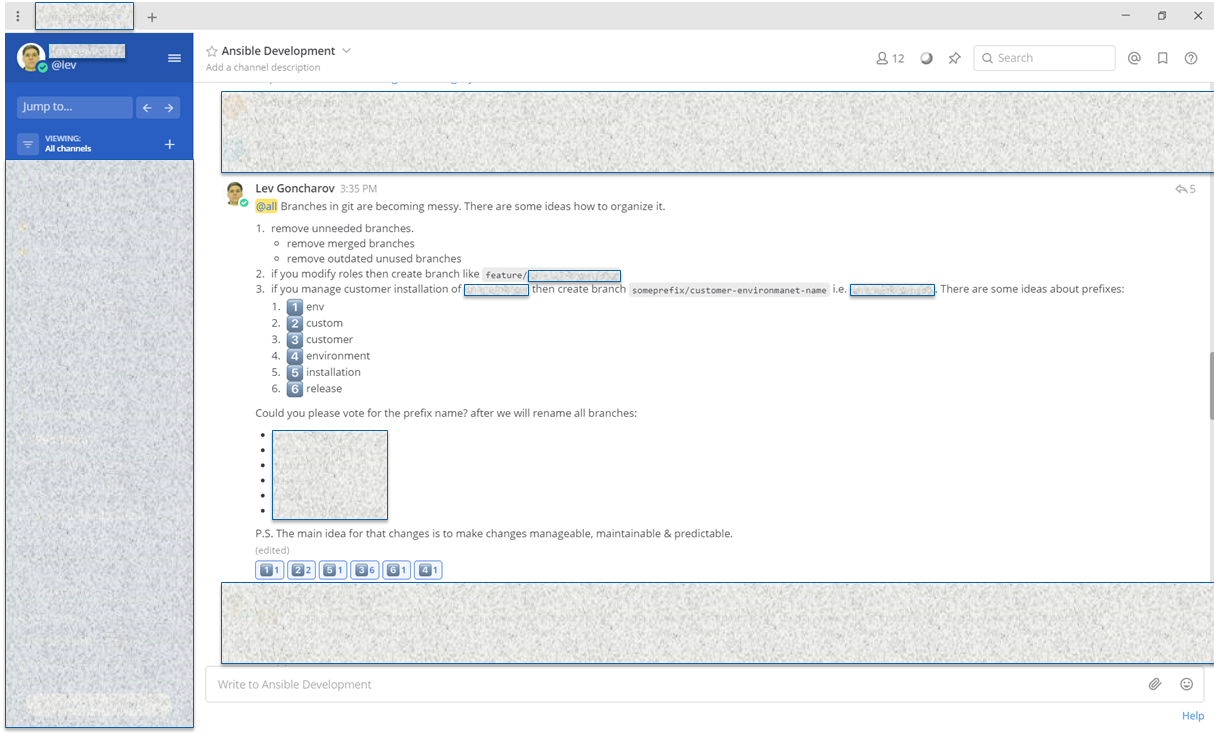
Наши реалии вносят коррективы, приходится подстраиваться. Есть разные подходы, например, использовать survey monkey или другой опросник, но с ними сложно вести обсуждения, это, скорее, собрать мнения. У нас на проекте используется Mattermost для внутренней переписки. Там, как и в slack, есть ветки сообщений, реакции, и на базе этих механизмов иногда делаем опросы/обсуждения, чтобы оперативно обсудить в малом круге заинтересованных лиц. На скриншоте пример обсуждения, какой префикс имени ветки использовать для клиентских окружений.
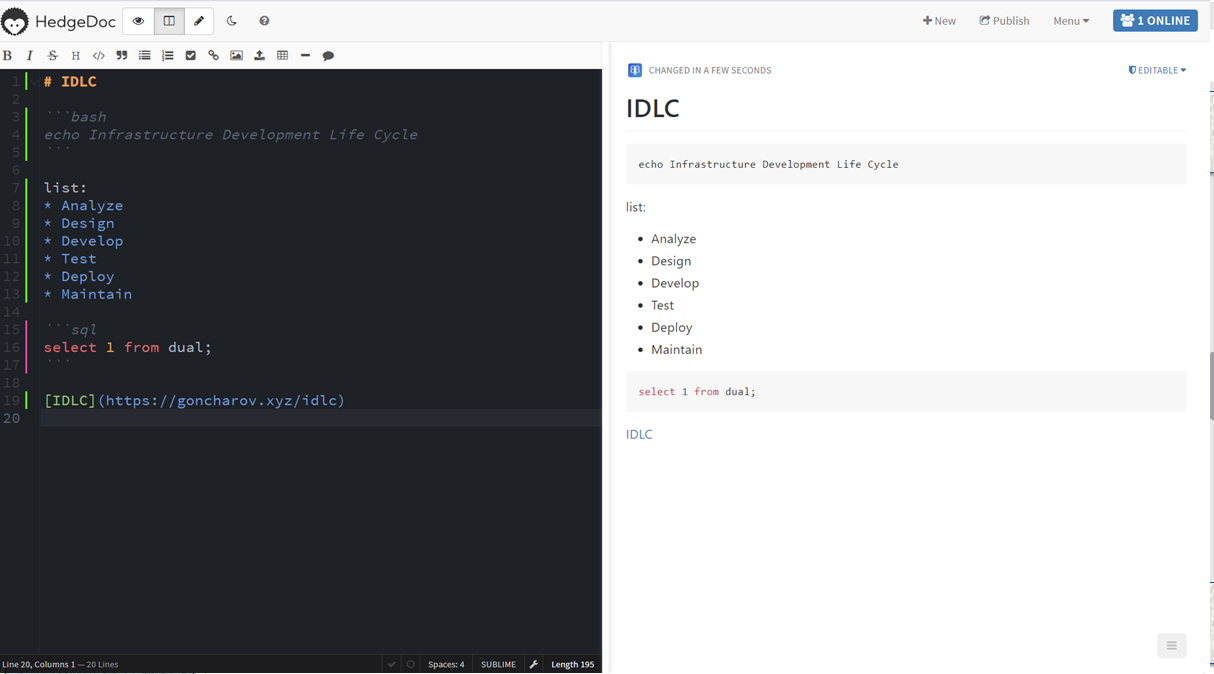
Для online мозгового штурма мы используем hedgedoc. Этакий google doc для совместного редактирования markdown-документов:
- Голосом во время созвона обсуждаем детали
- В markdown накидываем минутки / примеры кода / структуру репозитория итд
На выходе получаем протокол созвона, который можно разослать follow up письмом.
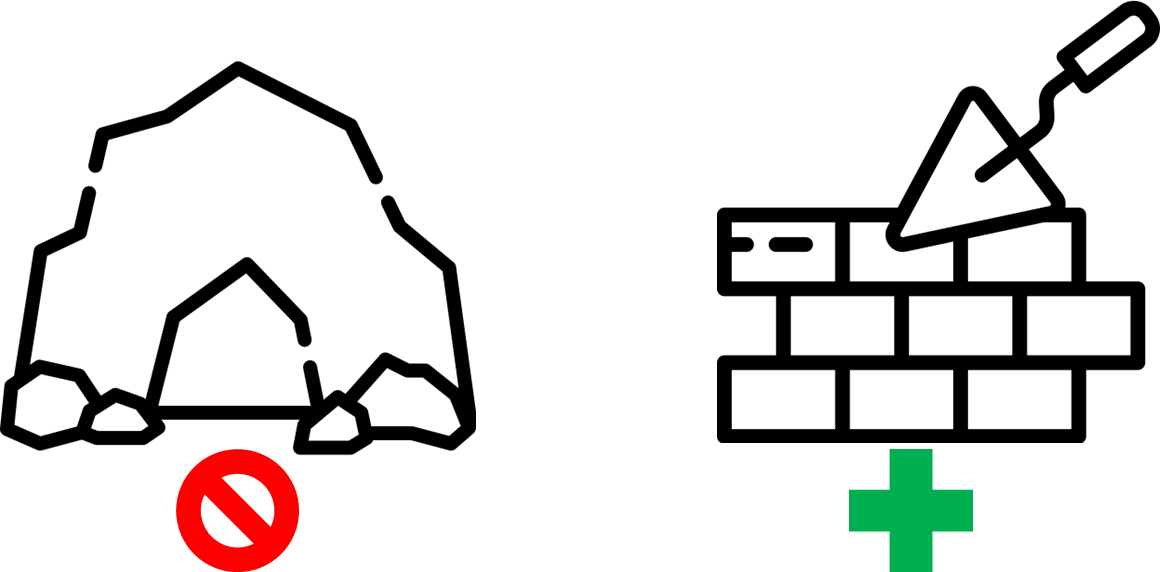
Основной концепт, которого придерживаемся на стадии дизайна - это не делать инфраструктуру из больших монолитных кусков, стремиться строить ее из простых, заменяемых / переиспользуемых частей. Например, если файл разросся до 1000 строк кода - пора его подробить на более мелкие.
Development
Только теперь можно приступать к написанию кода (читай IaC). Или нет? Как театр начинается с вешалки, так и разработка начинается с подготовки окружения для разработки.
Development environment
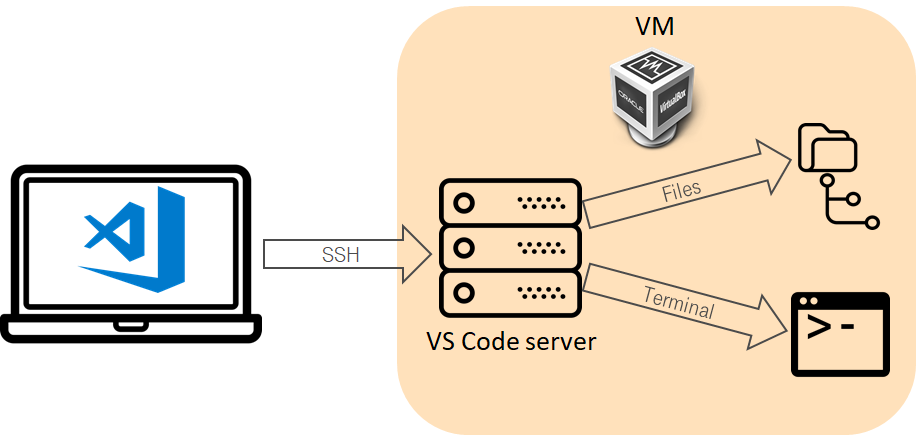
Подготовить окружение для разработки. Оно, кстати, тоже может и должно быть представлено в виде кода и храниться в репозитории. Я в основном использую связку vscode + remote-ssh / vagrant / ansible, такой подход позволяет унифицировать окружение и сделать воспроизводимым.
Development process
Непосредственно для разработки, можно переиспользовать множество практик из мира разработки ПО. Например, Green build master, когда код в мастер попадает только после прохождения тестов и code-review.
Test
Testing pyramid
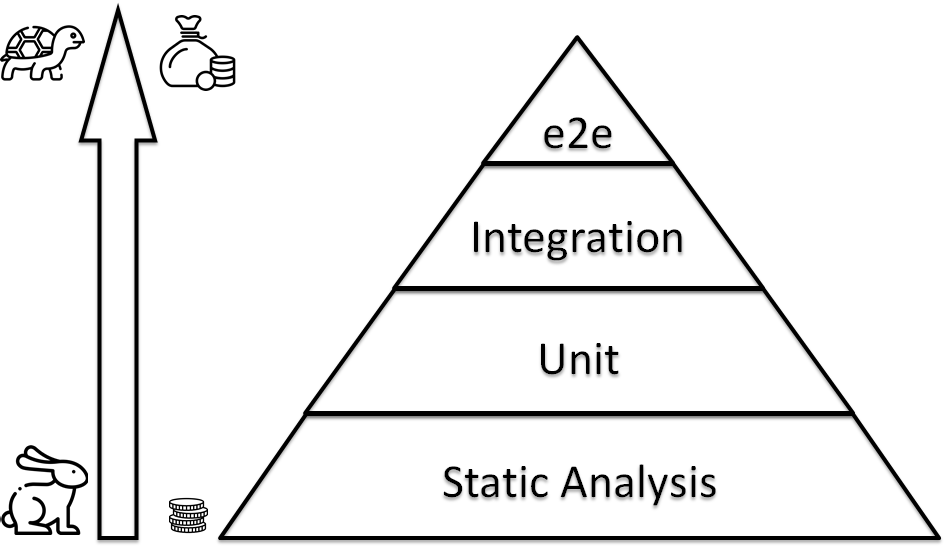
Думаю, многие не понаслышке знают про XP-практики и были часть этого процесса в разработке. В IaC все то же самое, но со своей спецификой. В основе у нас много дешевых тестов, например, линтеры, а на вершине уже развернутая инфраструктура из множества инстансов, где проверяются пользовательские сценарии.
Пирамиду тестирования IaC можно разделить на несколько слоёв:
- Static Analysis - Статистический анализ кода, без запуска. Линтеры, например.
- Unit - IaC должна состоять из простых кирпичиков, и вот их тестируем. В случае Ansible это роли, тестируемые при помощи Molecule.
- Integration - Очень похожи на unit, но представляют комбинацию ролей, описывающих целевую конфигурацию сервера.
- E2E - Цельная инфраструктура, состоящая из множества серверов.
Tests implementation
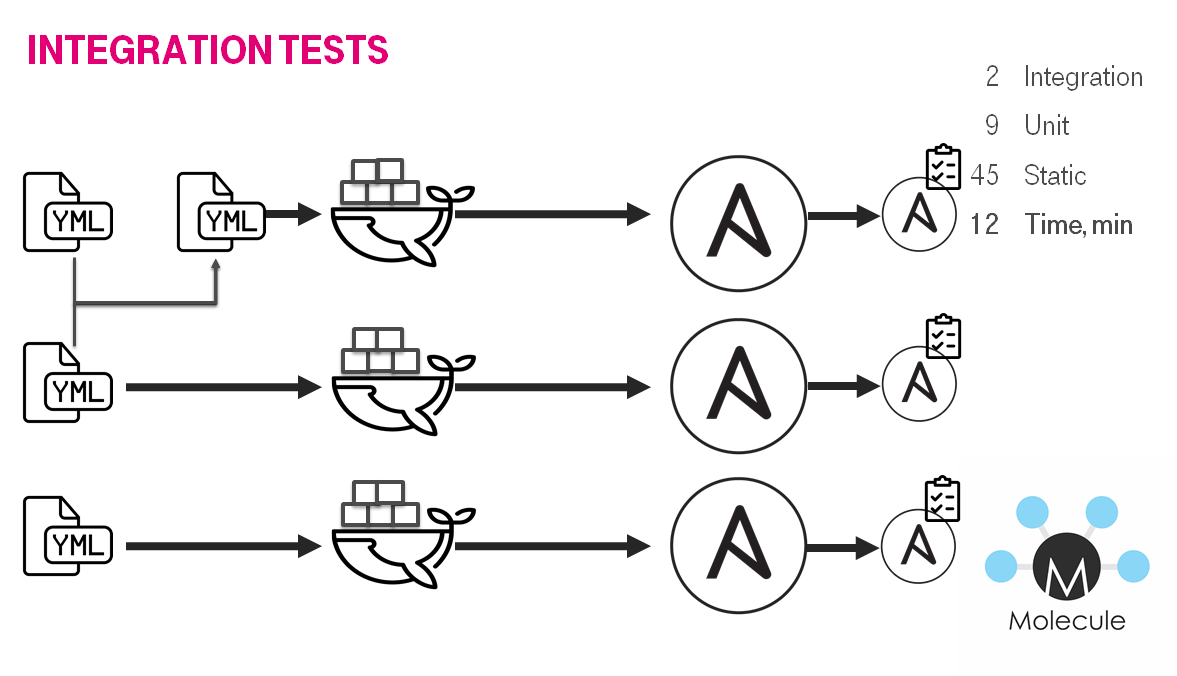
Тесты под капотом выглядит просто, но работают относительно долго (десятки минут). Например, для Ansible есть molecule, которая позволяет для каждой роли или плэйбука:
- Создать инстанс (docker container / виртуальная машина).
- Применить роль / плэйбук.
- Проверить идемпотентность.
- Верифицировать инстанс.
Можно почитать Что я узнал, протестировав 200 000 строк инфраструктурного кода или Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек.
When should I start testing my IaC?
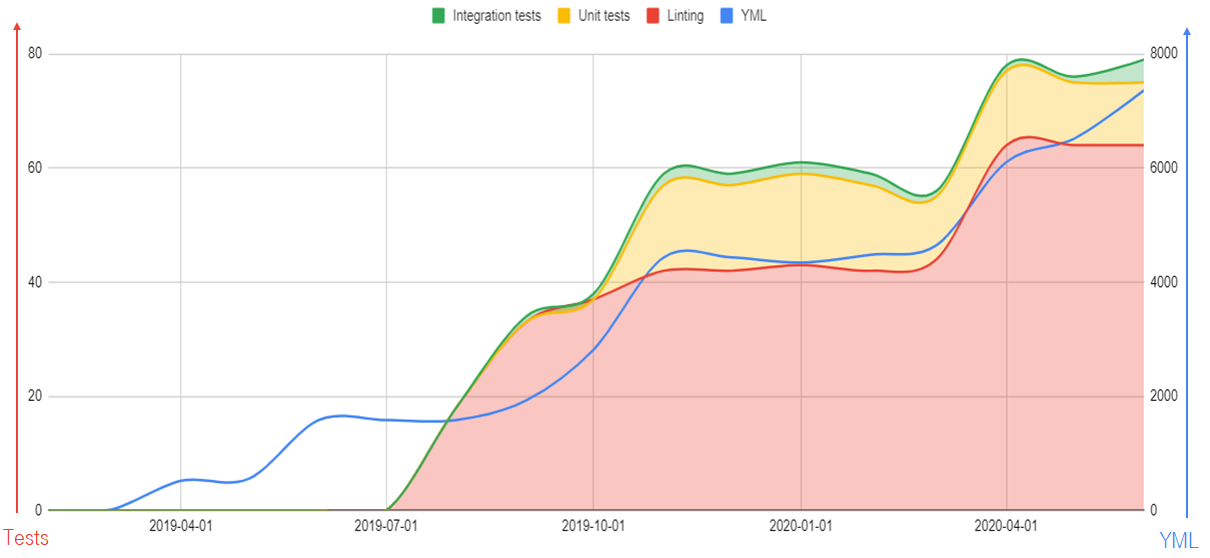
Когда же начинать тестирование? У меня сформировались такие ориентиры:
- 200 - линтинг должен быть.
- 2000 - пора делать юнит тесты
- 4000 - время интеграционных тестов.
- 6000 - E2E тесты мерещатся на горизонте.
Deploy
Deploy automation
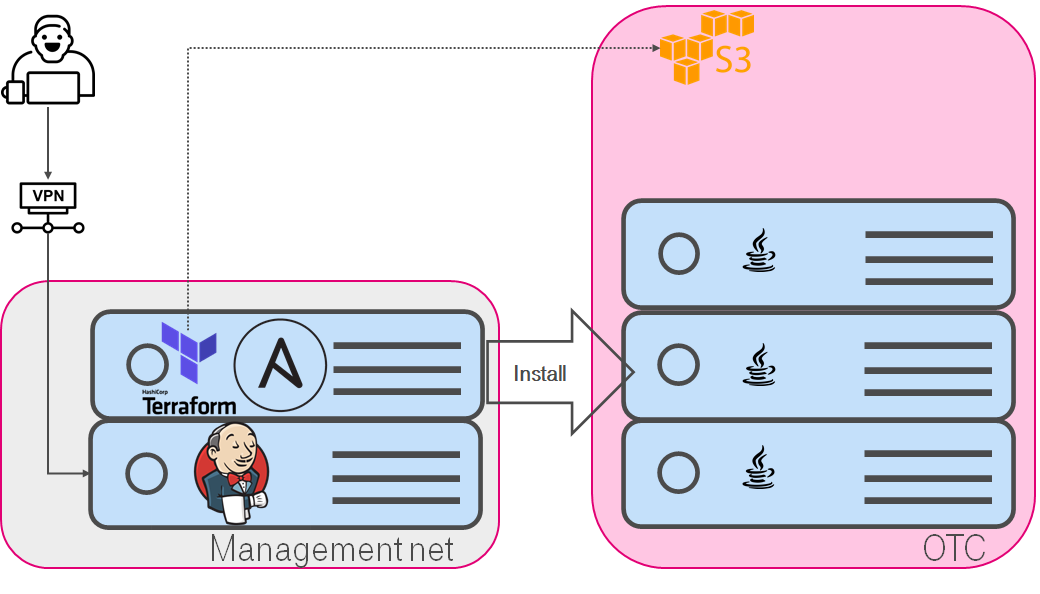
Стараюсь придерживаться парадигмы ухода от ручного запуска со своего ноутбука, а использовать воспроизводимые, контролируемые решения. Т.е. никто не мешает сделать jenkins job которая, например:
- Использую terraform приводит инфраструктуру к нужному состоянию.
- Запускает Ansible.
Естестественно, вместо jenkins можно использовать awx / ansible tower / gitlab, это скорее отсылка к тому, что у вас на проекте уже есть CI/CD и можно переиспользовать его. Также надо помнить, что с большой силой приходит и большая ответственность. И такая автоматизация без должного внимания (тесты, ревью итд) может наломать дров.
Air gap
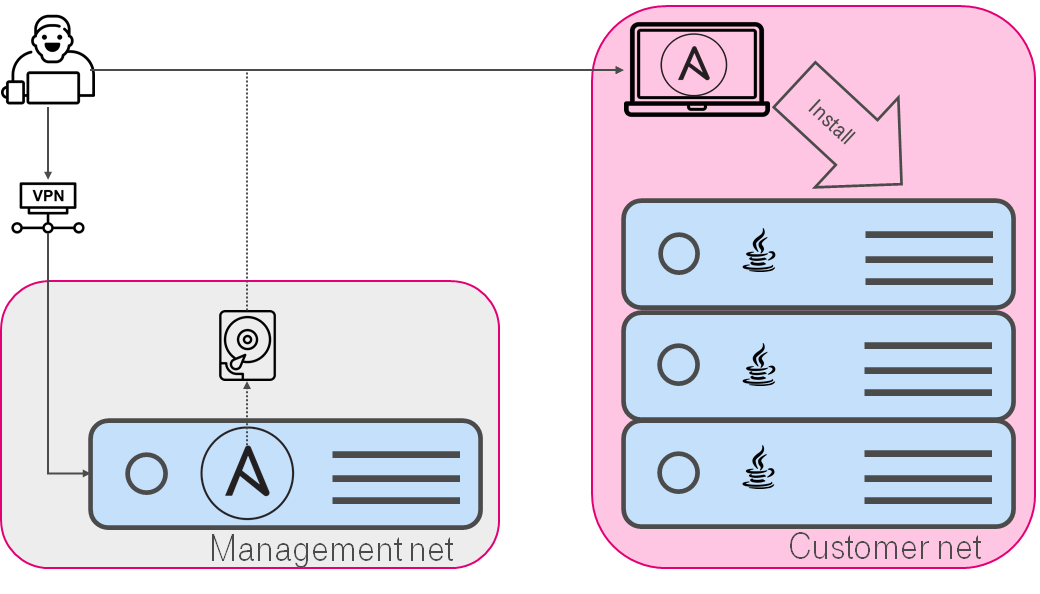
Безусловно, не всегда полная автоматизация возможна. Что делать, если у вас air-gap (читай нет прямого доступа) до заказчика? Тут тоже возможны варианты упрощения жизни. В нашем случае мы решили это, разбив деплой на 2 части:
- В нашей сети
- запускаем Ansible с нужными тэгами, который собирает нужные артефакты.
- Копируем получившийся “пакет” на флэшку.
- Идем ногами к заказчику.
- В сети заказчика заказчика
- запускаем Ansible с нужными тэгами.
- Установка идет как обычно подхватив заранее скопированные артефакты.
В этой схеме актуальны тесты. т.к. без них велика вероятность нарваться на нерабочие плэйбуки / роли. И согласитесь, об этом крайне неприятно узнать у заказчика, когда потрачена уйма часов на дорогу и согласования.
Maintain

Инфраструктура не статична, он как живой организм изменяется во времени. Но, как правило, она стремится к хаосу. И это нормально. Если у вас договоренности об IaC формализованы, то ее проще поддерживать и вносить изменения. На графике выше пример того, что кол-во IaC растет, но за счет тестов кол-во людей поддерживающих константно. Кому интересно, то можно почитать Agreements as Code: как отрефакторить инфраструктуру и не сломаться.
Evaluation
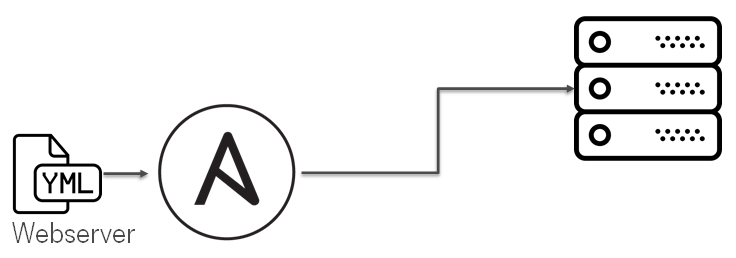
Предлагаю на примере настройка простого web-сервера посмотреть эволюцию IaC. Изначально это простой playbook, который содержит в себе весь код и справляется с задачей настройки инстанса.
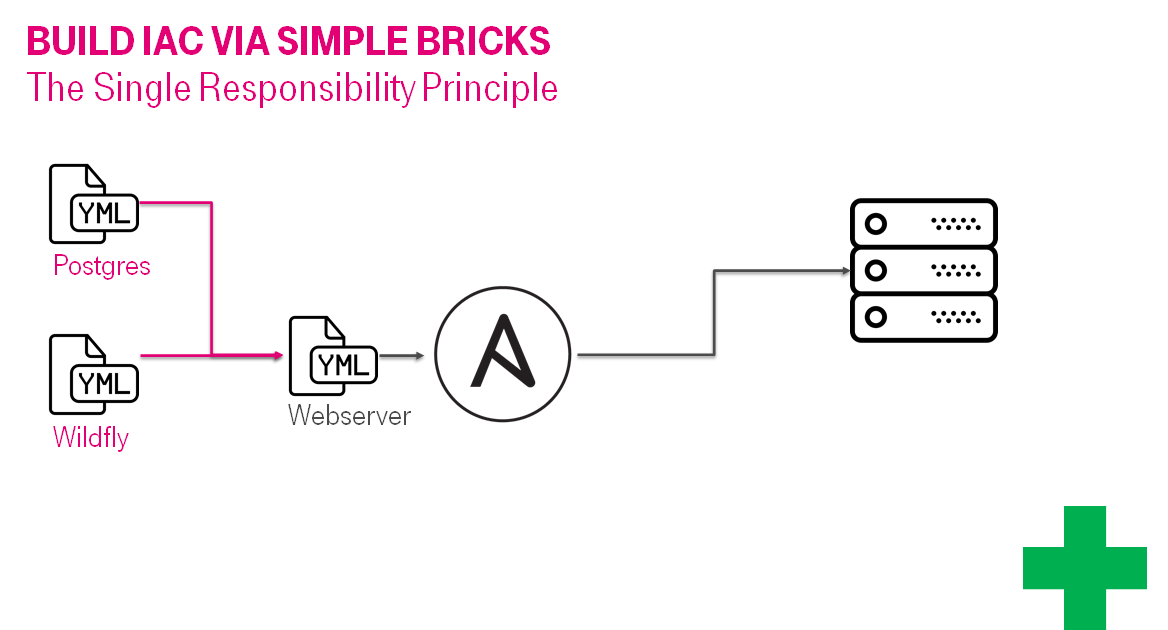
Со временем код может разрастить, за счет обработки краевых условий, фиксирования договоренностей и прочего. И начиная с условных 500 строчек кода, будет смысл его раздробить на 2 роли: Настройка БД отдельно, web сервера отдельно. Т.е. мы строим инфраструктуру из простых переиспользуемых кирпичиков (привет дизайн сессии и тесты).
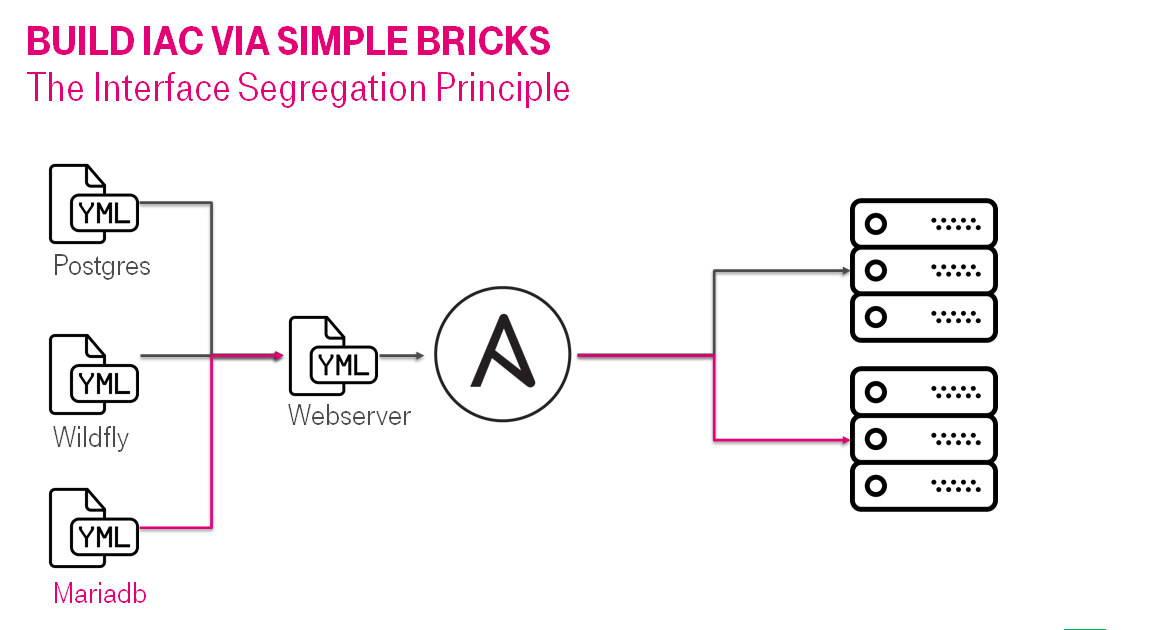
Со временем может появиться потребность расширить количество поддерживаемых платформ / web серверов. И где-то в этот момент размер плэйбука снова станет расти до катастрофического размера.
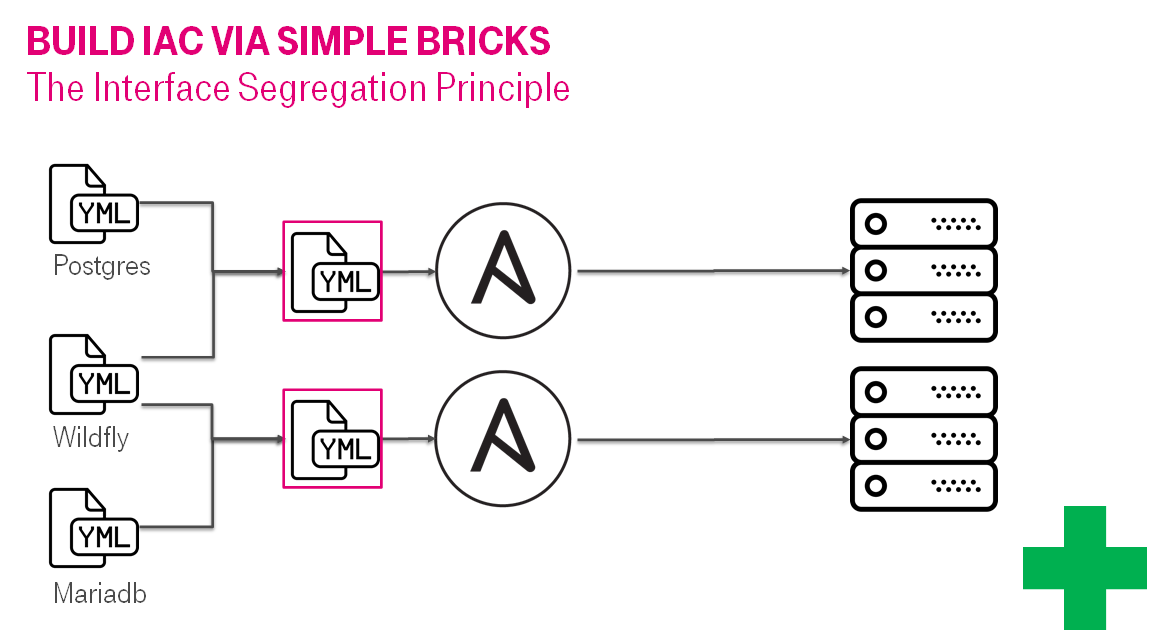
Это подходящий момент раздробить сложный плэйбук на несколько простых. И так может продолжаться до бесконечности, повышая сложность системы экспоненциально. Скорость этого роста будет придерживаться за счет ревью.
End

Нельзя просто так взять ansible playbook, положить в git и сказать, что у меня IaC. Необходимо побеспокоиться о процессах вокруг. Благо нет необходимости изобретать велосипеды, т.к. в инфраструктуре, с некой долей изоморфности, процессы проходят так же, как и в разработке.
Links
- Slides
- Video
- IaC Development Life Cycle [ENG]
- A list of awesome IaC testing articles, speeches & links
- How to test Ansible and don’t go nuts
- Agreements as Code: how to refactor IaC and save your sanity?
- Lessons learned from testing Over 200,000 lines of Infrastructure Code
- Ansible: CoreOS to CentOS, 18 months long journey