Lev Goncharov
Infrastructure simplifying engineer
Как наломать велосипедов поверх костылей при тестировании своего дистрибутива
Date: 2018-01-09
Это текстовая версия выступления на Devopsdays T-systems 2018-03-02 и Hashicorp meetup 2018-02-08.
Диспозиция
Представим на минуту, вы разрабатываете программно-аппаратный комплекс, который базируется на своем дистрибутиве, состоит из множества серверов, обладает кучей логики и в конечном счете это все должно накатываться на вполне реальное железо. Если вы впустите бяку, пользователи вас по головке не погладят. Всплывают три извечных вопроса: что делать? как быть? и кто виноват?
Далее по тексту будет история, как начать стабильно релизиться и как к этому пришли. Чтобы не растягивать статью, не буду говорить про модульное, ручное тестирование и все стадии выкатывания на продуктив.
Сначала было MVP
Сложно сделать сразу всё и правильно, особенно, когда конечная цель точно не известна. Первоначальный деплой на стадии MVP выглядел примерно так: никак.
make dist
for i in a b c ; do
scp ./result.tar.gz $i:~/
ssh $i "tar -zxvf result.tar.gz"
ssh $i "make -C ~/resutl install"
done
Скрипт конечно упрощен донельзя для передачи сути, что CI нет. С машины разработчика на честном слове собрали и залили на тестовую среду для показа. На данном этапе тайное знание настройки серверов сидело в головах разработчиков и немного в документации.
Проблема в том, что есть тайное знание как заливать.
Фигак-Фигак и на staging
Исторически сложилось, что teamcity использовался на множестве проектов, да и gitlab CI еще тогда не было. Teamcity был выбран за основу CI на проекте.
Разово создали виртуальную машину, внутри нее запускались “тесты”
make install && ./libs/run_all_tests.sh
make dist
make srpm
rpmbuild -ba SPECS/xxx-base.spec
make publish
тесты сводились к следующему:
- в полуруками предподготовленном окружении установить набор утилит
- проверить их работу
- если ок - то опубликовать rpm
- в полуручном режиме сходить на staging и накатить новую версию
Стало лучше:
- теперь в мастере лежит что-то проверенное
- знаем что в каком-то окружение работает
- отлавливаем детские ошибки
Но чувствуете боль?
- проблемы с зависимостям (часть пакетов пересобрана)
- окружение для разработки каждый разворачивает как умеет
- тесты гоняются в каком-то непонятном окружении
- сборка дистрибутива, настройка инсталляции и тесты - три разные несвязные вещи
Делаем мир чуточку лучше
Такая схема прожила какое-то время, но мы ведь на то и инженеры, чтобы решать проблемы и делать мир лучше.
- Зависимости всего дистрибутива вынесены в метапакет
- Был создан шаблон виртуальной машины используя средства vagrant
- Bash скрипты создания инсталляций переписаны на ansible
- Создана библиотека для интеграционного тестирования, чтобы проверять что система работает в целом правильно
- Часть сценариев покрыта через serverspec
Это позволило:
- Сделать идентичным окружение разработки/тестирования
- Держать код развертывания вместе с кодом приложения
- Ускорить включение в процесс новых разработчиков
Такая схема прожила весьма долго, т.к. за приемлемое время (30-60 минут на билд) позволяла отлавливать множество ошибок, не доводя их до ручного тестирования. Но осадочек был, что при обновление ядра или при откате какого-то пакета всё шло наперекосяк, и где-то начинал грустить щенок.
Становится жарко
По ходу пьесы появлялись различные проблемы, которые потянут на отдельную статью:
- Прогон интеграционных тестов со временем стал затягиваться, т.к. шаблон виртуальной машины стал отставать от актуальных версий пакетов. Пару месяцев пересобирали в полуручном режиме. В итоге сделали, чтобы при выпуске релиза:
- автоматом собирался vmdk
- vmdk прицеплялся к виртуальной машине
- полученная VM паковалась и заливалась в s3 (кстати, кто знает как vagrant подружить с s3?)
- При одобрении мерджа не виден статус билда - переехали на gitlab ci. Обошлись малой кровью - пришлось отказаться от тригера некоторых билдов по регулярке тэга, в остальном рады.
- Раз в неделю была рутина по выпуску релиза - автоматизировали:
- Инкремент версии релиза
- Генерация release notes по закрытым задачам
- Обновление changelog
- Создание merge requests
- Создание нового milestone
- Чтобы ускорить билды - часть шагов была вынесена в docker, как то: линтеры, нотификации, сборка документации, часть тестов итд итп
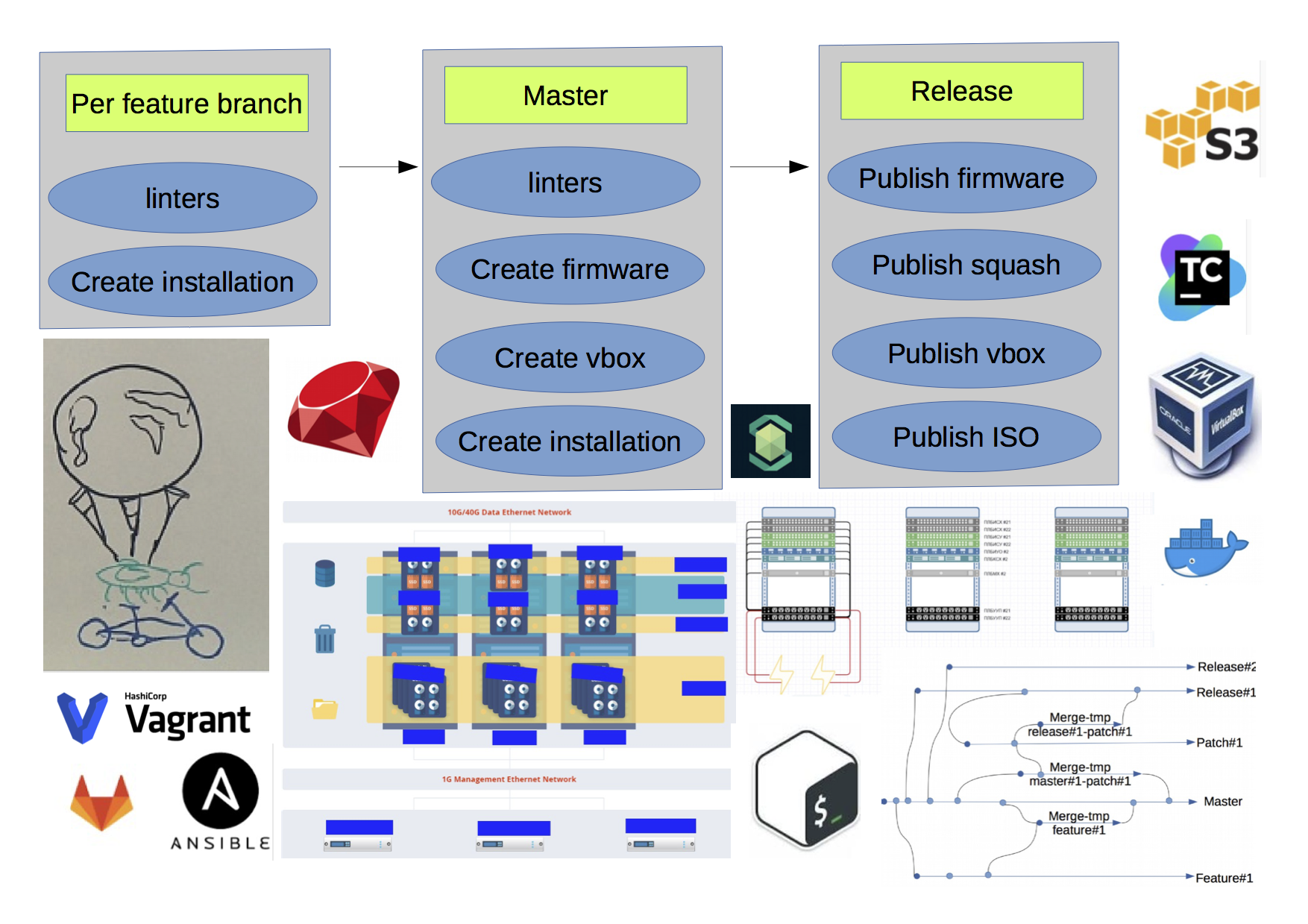
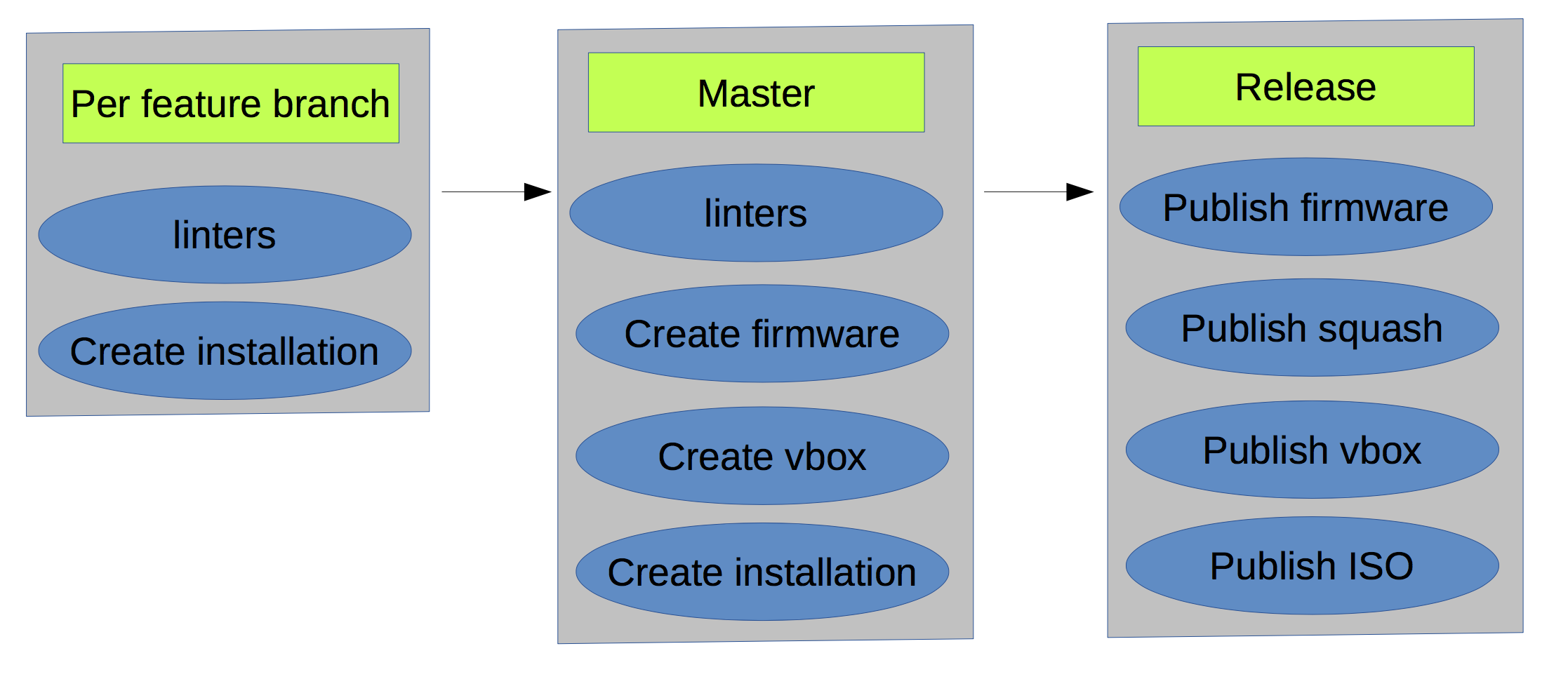
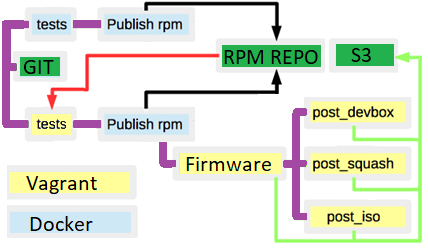
Несколько упростив, конечная схема получилась такая(красным обозначены неочевидные связи между билдами):
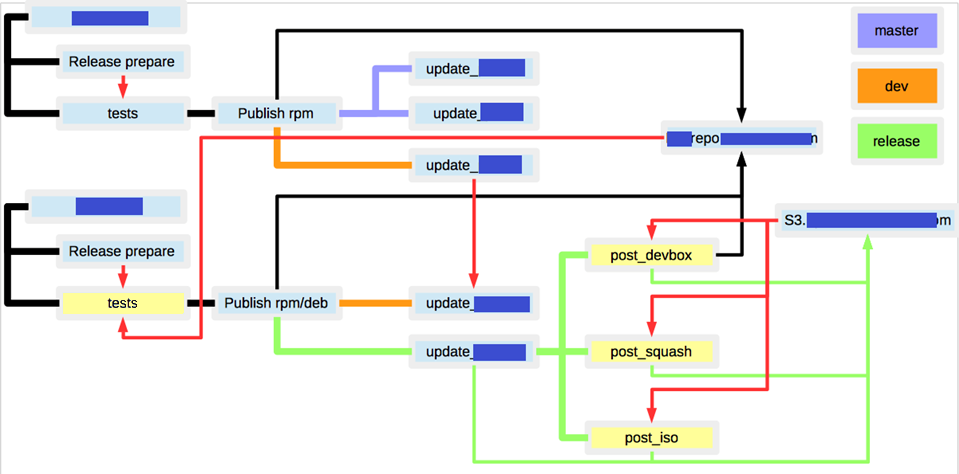
- множество RPM/DEB репозиториев под разрабатываемые пакеты
- S3 хранилище для хранения артефактов(firmware, squash, iso, VM templates)
- если по одному и тому же бранчу запустить сборку дистрибутива, то результат может получится различным, т.к. зависимости между пакетами прописаны не жестко, и состояние репозиториев могло измениться
- множество неочевидных связей между билдами
Это позволило:
- Выпускать приватный релиз раз в неделю
- Повысить скорость разработки за счет уменьшения кол-ва конфликтов и увеличения прогонов тестов
Заключение
Сложно полученный результат назвать идеальным, но с другой стороны готовых решений для задач такого рода не встречал. Основные посылы из этого опуса:
- дорога в тысячу ли начинается с первого шага (с)
- есть боль - уменьшайте ее.